
TL;DR:
After a year of chasing 100% accurate AI-powered analytics through ever-more-complex approaches (and failing), we learned the secret: don't try to teach AI your business logic—let your data team encode it once in a semantic layer. Now our LLM achieves near-perfect accuracy by working with human-defined metrics instead of raw SQL. Sometimes the best AI solution is knowing when to keep humans in the loop.
Introduction
For as long as the term 'big data' has existed, teams have dreamed of the promised land of self-serve analytics. A world where every person in an organization can access accurate, up-to-date, and aligned insights about business operations (Business Intelligence being the buzzword for this). For over a decade, entire industries have emerged, attempting to solve this problem through ever more sophisticated tooling for analysts to build and deploy dashboards consisting of pre-defined charts, tables, and static narratives around the data's meaning.
These dashboards only ever solved half the problem. They made accurate data available to team members (up to the analyst's discretion), but many team members lacked the technical expertise or time to dig into nuances, edge cases, or interpretation errors. Anyone who has maintained a dashboard has certainly received at least one urgent message along the lines of: "Adam - our Sales dash is not agreeing with the company dash on Q4 revenue." Only to find that the discrepancy was due to how the dashboards reported revenue. In this case, only an analyst or a technical team member willing to dig into data definitions could explain this.
Enter GenAI with the promise to finally solve the latter half of self-serve BI, serving up an analyst on demand who can interpret data, write new queries, and answer questions. Unfortunately, it turns out that AI falls victim to the same interpretation problems humans do, limited by context windows and lack of training (pre or post) on proprietary company ontology and business logic. Even worse, in spaces such as startups, these ontologies and business logic definitions are constantly changing. For example, even with RAG over indexed content, along with table definitions and descriptions, we still often saw the LLM conflate our customers' activity (e.g., placing orders) with our activity (e.g., closing deals)—a semantic and reasoning error in application of business logic.
The Decision Context Problem
The decision context problem arises when teams lack crucial business context: gaps in what they know, how it applies to what the company aims to achieve, and how decisions are made day to day. A major input to this has always been quantitative data, and it remains one of the main ways organizations address this problem today. The techniques for making use of quantitative data to inform decision-making have evolved considerably, but the truth remains the same: to make optimal decisions, accurate data is necessary to root options and criteria in fact.
Think of all the decisions you have to make related to your role. These may span:
- Hiring - Compensation and market comparisons inform reasonable offers. Team velocity and outstanding work inform hiring prioritization.
- Project Prioritization and Roadmapping - Customer usage patterns, team velocity, and open work all come in the form of quantitative data, helping to inform what is worth investing in and what is reasonable to invest in.
- Funding - Any founder who has gone through a funding round knows that having a solid understanding of the current state of your business and future potential is necessary for getting competitive offers; much of this information comes in the form of quantitative data.
The list goes on. I would challenge you to think of a situation in which you did not need to use any quantitative data in your decision-making (or would not have benefited from having it).
Convictional exists to solve the decision context problem, but until recently, we lacked the ability to work with your data within Convictional itself. Given the importance of data in the decision context problem, and in particular the importance of accurate data, we took a long journey before landing on a technique we feel confident in.
Just Throw an LLM at It!
This was our first thought, at least, back in the early days of 2024. GPT-4 had recently come out, and Anthropic was cooking—why not take the latest and greatest state-of-the-art model and just give it a SQL tool capable only of SELECT statements and some retrieved context? Surely it would finally be the solution to the self-serve analytics problem. Right? Well, not quite.
Our initial setup can be seen in the flowchart below, which took the naive approach of retrieving related context given the user query (using a hybrid search over indexed company documents in GitHub and our knowledge base), checking for metric supportability given available tables and their definitions, and implementing some self-reflection for error correction:

The most common error we saw was poor interpretation of context into business logic. Querying individual, pre-defined columns was fine, but any complex query requiring mixing of columns or joins to other tables introduced semantic errors. For example, in our dropship days, our customers tracked 'orders' processed between them and their B2B partners; the LLM consistently confused these 'orders' with our 'sales deals', leading to incorrect conclusions about performance and implications. Overall, we saw an approximately 40% error rate on test queries.
In our prior line of business, we offered natural language to SQL via this technique over only the data in Convictional. This worked because we could prompt-engineer ourselves out of regular semantic issues due to the fact that we owned the schema and definitions. Customers wanted to integrate their own data into the pipeline, but given the high error rates we saw above when applying to an unknown schema, we weren't able to entertain this feature.
Try Adding More Structure!
We next explored using knowledge graphs to represent semantic relationships among entities within the organization and the underlying tables. We went deep on this one, seeing the graph as the potential answer to the semantic understanding of proprietary business logic and syntax. LLMs allowed us to quickly construct knowledge graphs given underlying business context, leading to massively complicated structures attempting to capture all business-relevant entities along with their relationships.

Around this time, Microsoft released their GraphRAG framework, which seemed to validate this direction. While quantitative data understanding was not the only motivation for using graphs to model knowledge, it was a strong one. We felt that if we could accurately model the relationships of entities, then when asking a question about "how many sales deals did we close in Q4", the LLM would be able to deterministically move from a sales-related node to the "deals" node, and then drop down from our entity layer to the schema layer and use the appropriate table and columns. The idea was sound, and when we developed agents capable of traversing the graph using graph-algorithm-powered tools, we saw that they could indeed move from nodes to associated tables and historical queries. However, what we realized was that we had effectively moved the schema misinterpretation up a level into the graph building.
Using our eyes and agents to explore the graphs produced, we saw similar semantic mistakes appearing in the relational structure of the graph (for example, poor team assignments, project ownership misattribution, semantic name confusion, etc.). Further, even in smaller, more targeted ontologies, the graphs did not generally outperform our hybrid search over indexed content chunks. Later, we would better understand the reason for that, but that's a story you can check out in a different essay here.
Ultimately, the approach to knowledge graphs that we took was not the optimal structure for knowledge or for representing and linking business logic to underlying quantitative data.
Getting Closer
Following the knowledge graph-based attempts, and outside of small revisits as new models were released, we shelved our efforts to bring quantitative data to Convictional in order to focus on other feature priorities (and we introduced a lot in that time, including meetings, threads, goals, discussions, tasks, and updates). However, in March 2025, we became aware of an approach using human query verification and caching (vanna.ai) that had been open-sourced and served as inspiration to revisit quantitative data.
We designed an LLM workflow to experiment with this approach, in which I developed 25 test queries and worked with the workflow to verify and cache queries produced by the LLM with access to historical queries and table metadata (see flowchart below):

Performance jumped from the ~60% we had seen in our previous experiments to 75-85%. However, issues still remained:
- Even 85% isn't good enough for self-serve analytics. Highly repeated queries became solid quickly as the LLM pulled on previous queries of the same analytic/question, but any novel queries or edge cases required human verification and correction.
- Schema drift and cache staleness would become acute—particularly at smaller organizations growing quickly and seeing frequent updates to their schemas and models (don't ask how many migrations our team has performed in the last year).
- Data analysts become LLM QA, which may not be great for talent retention. In this framework, new queries generated by the LLM have to be sent to the human to review and correct, effectively moving the 'fun part' of answering the question to the LLM.
Promising, and the key insight of humans in the loop led us to our final iteration: the version of Analysis Mode within Threads that we currently offer in Convictional.
It Was in the Name the Whole Time
A Semantic Layer can be thought of as a recipe book for business metrics. Sitting between your modeled data and business intelligence layers, the semantic layer contains detailed descriptions of columns, their type (are they an entity, a dimension, or a measure?), and how they can combine to define business metrics (e.g., quantitative expressions of your business logic). Data teams are beginning to more holistically adopt the semantic layer as a solution to more robust business intelligence layers, with dbt reporting that approximately 10% of customers currently use the semantic layer, and another ~30% plan to implement in the next 12 months, representing a 300% increase in adoption of a new technology. Based on user feedback, we are also looking at integrating with other semantic layer providers.
We use dbt to manage our transformations and, now, semantic layer for Convictional's own data. It was a natural fit for this project as we could effectively allow for what we had originally offered in our dropship platform (natural language to SQL over tightly controlled definitions), but as an integration that immediately brings analytics to Convictional.
We leveraged the MCP tool pattern to build a true production-grade, multi-tenant capable dbt semantic layer tool that is able to not only query metrics but also explore data definitions and lineage. This solved two problems for us:
- Query accuracy jumped to near 100% as the LLM was now working with concrete measures defined by humans and never needed to write SQL itself. Further, the LLM could identify when it didn’t have access to the required data (outside of hallucinations which take place further upstream in the model).
- The robust definitions and access to data lineage mean that the LLM sees the 'whole picture' of where the data came from, allowing it to add narrative and answer questions about what the data means.
Our users can now get access to their data in seconds or minutes, as opposed to hours or days when they had to rely on submitting tickets or requests with their data teams.
Presenting this tool in a chat framework (our Threads feature) means that the user can ask the LLM what measures it can query and what they mean before the LLM begins its analysis. Further, the LLM can easily visualize many of the metrics it queries using Chart.js, rendering charts directly in chat—basically bespoke dashboards for the given question, underpinned by human-verified robust data.
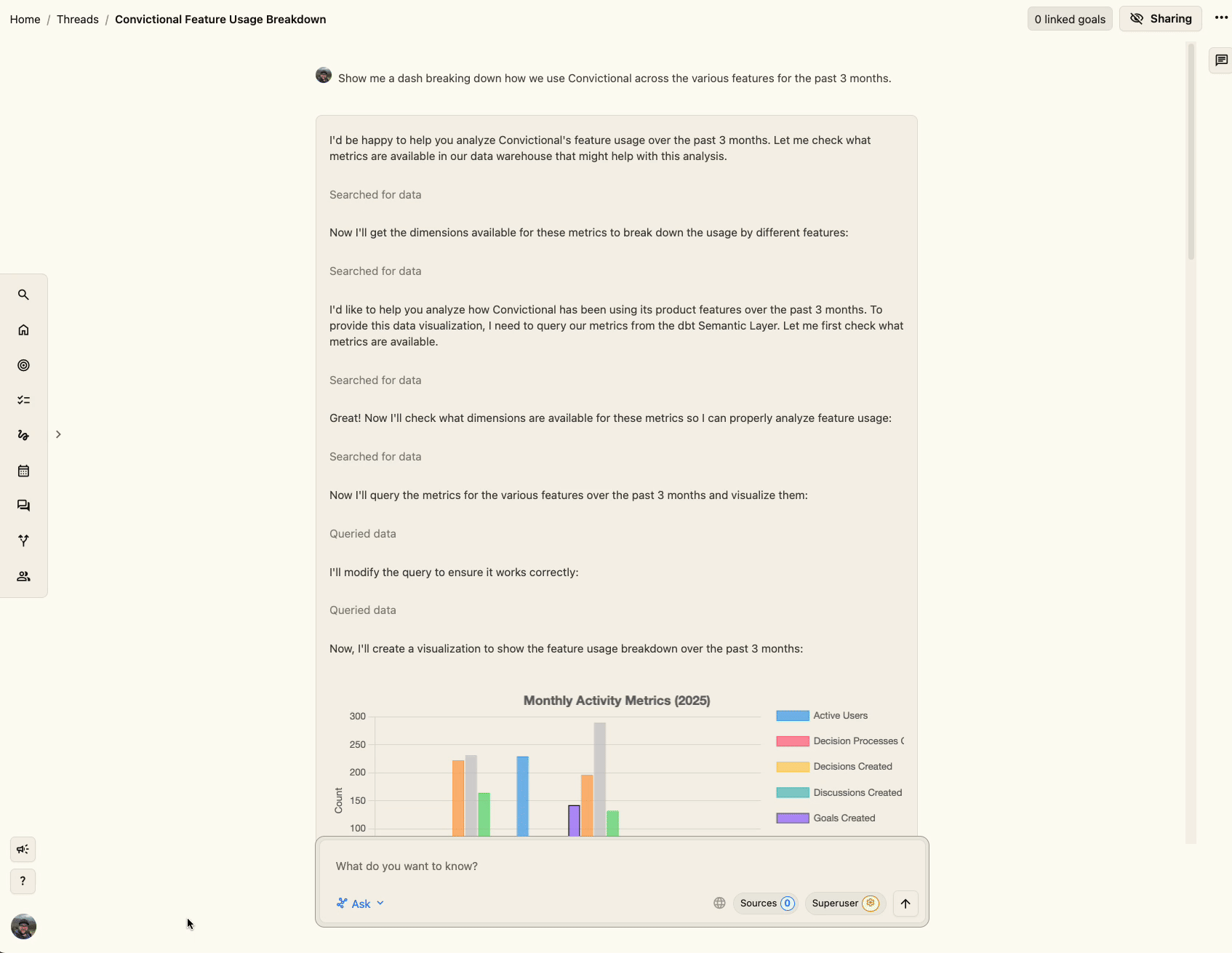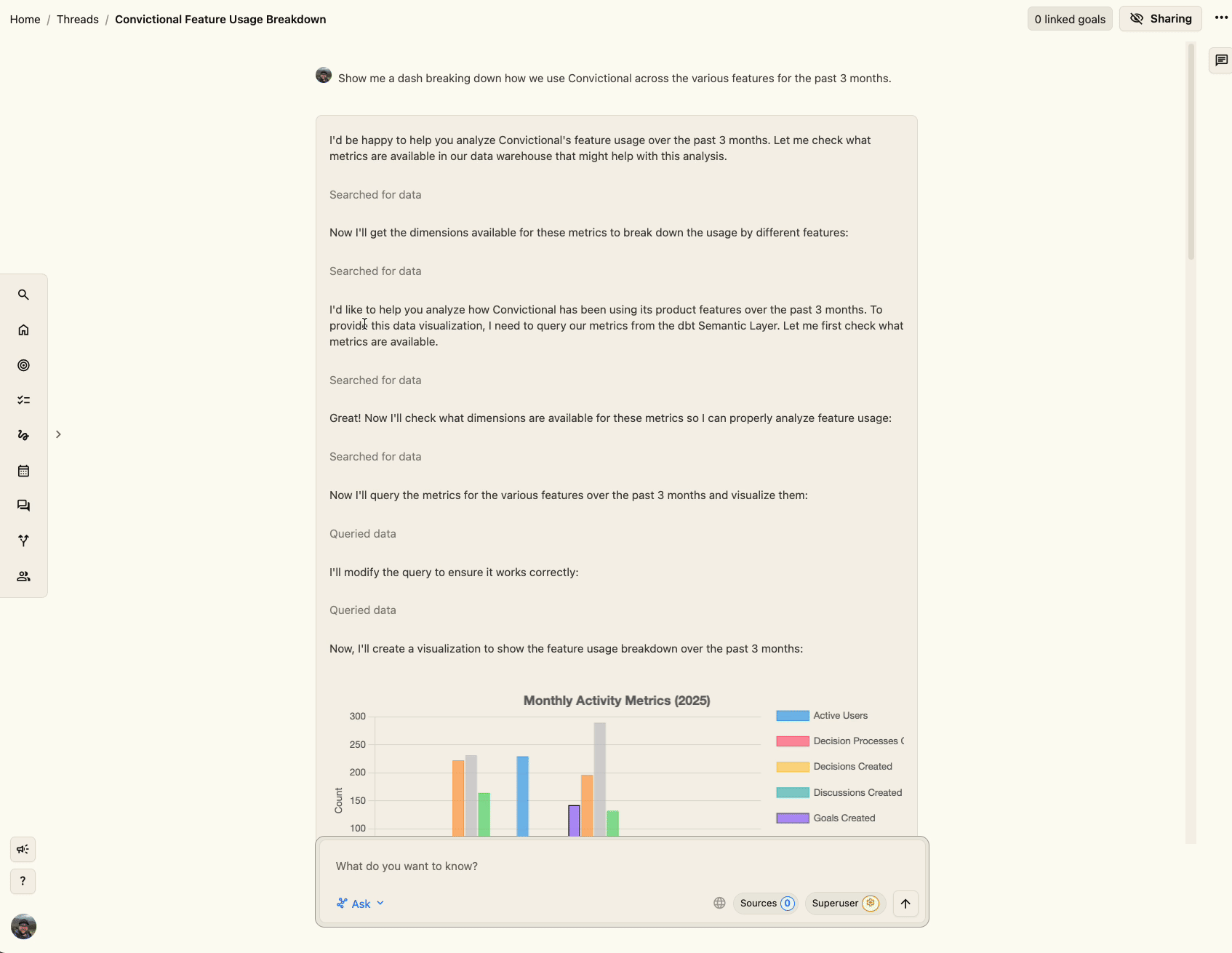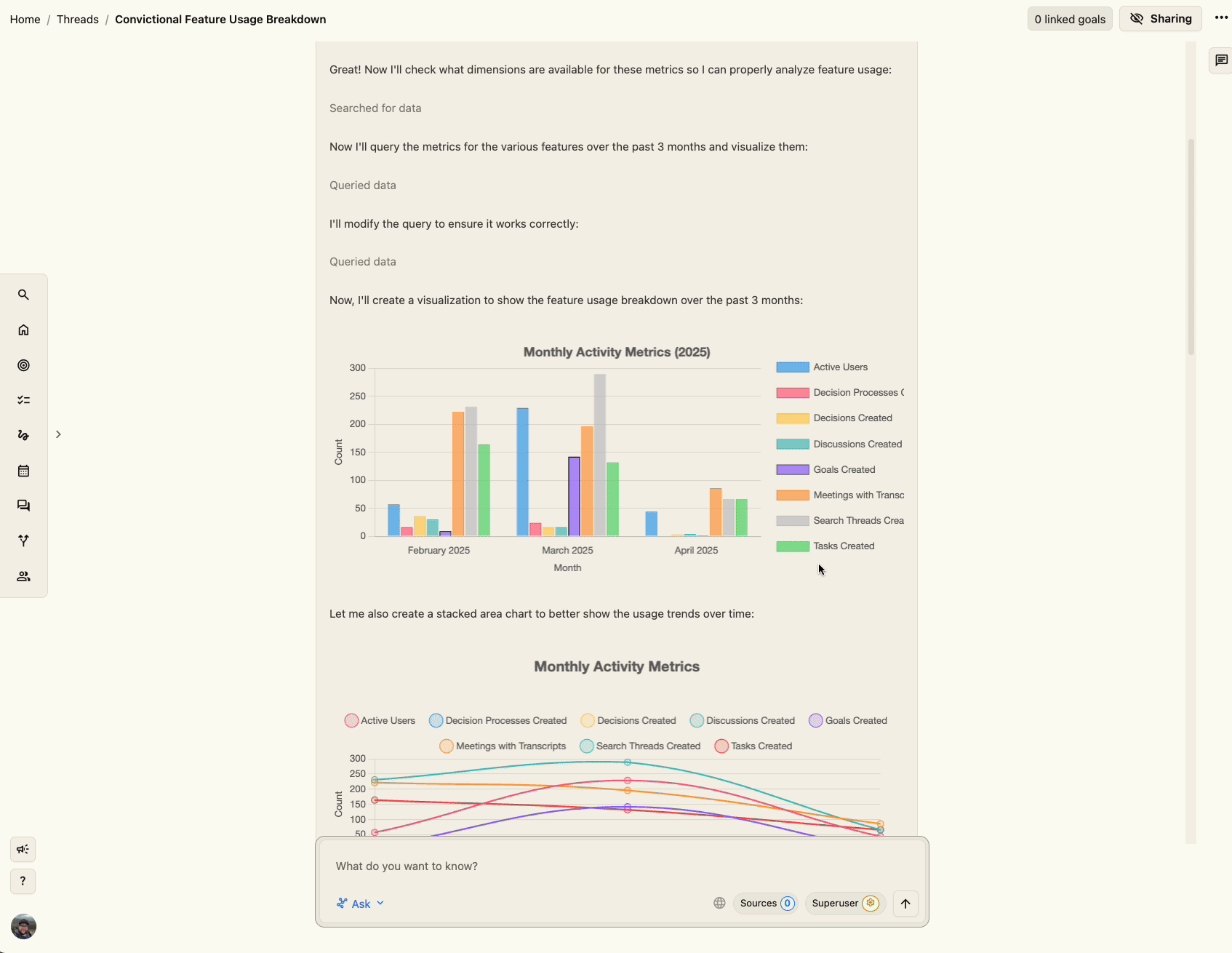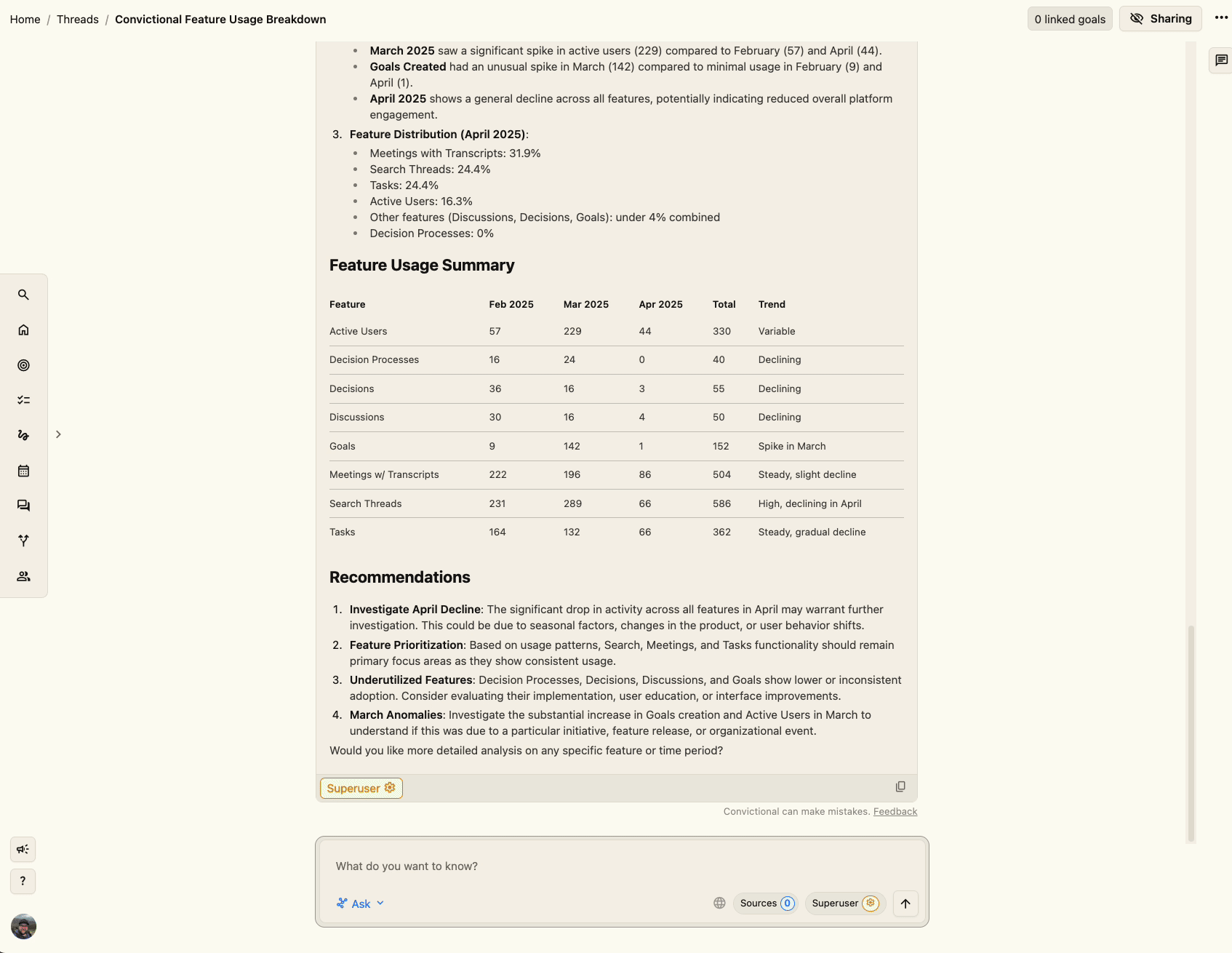
What Did We Learn?
A primary insight throughout this process is to not devalue your human experts. As we've learned throughout the study of the decision context problem, the tacit knowledge that exists in people's heads is often the most valuable information. Finding a way to bring your experts in at the right point in order to maximize their leverage is the real breakthrough—not more complexity or fancier structures. In our case, looping humans into the point of semantic layer definition scaled their effect by giving downstream LLMs access to accurate and robust metrics for reporting. Humans modelling the data was too early and left too much to the LLM, humans verifying queries was too late in the process putting undue review pressure on them - the goldilocks zone was the semantic layer.
Additionally, UX is key, both for the user trying to answer their questions and the human experts unlocking the pipeline. We are far from solving that problem entirely and have largely drafted off of other patterns emerging in LLM clients (e.g., ChatGPT, Anthropic's Claude.ai), but it remains a core focus for us.
What's Next?
With a solid technique found, we have begun to move onto the UX problem of how best to present and work with your data. While chat seems natural, we don't believe it's the final form. We believe that the analysis should meet you where you are—this involves exploring more agentic behaviors throughout the platform, which is underway.
Further, there is still a heavy human-in-the-loop aspect, which we believe in, so we want to enable UX that allows non-technical users to collaborate with their data teams when metrics for a given question aren't available in the semantic layer.
However, as of today, if you have (or plan to have) a semantic layer defined in dbt, we can help you set up your own analyst on demand in Convictional. Check us out at convictional.com (free to sign up and try it out)!